Overview
TinyLFU はアクセス頻度を近似し、軽量でハイパフォーマンスに設計されたキャッシュアルゴリズムです。最近、Database Internals を読んでいて TinyLFU を知ったのですが、Database Internals では TinyLFU の詳細が書かれていなかったので、TinyLFUが提案されている論文を読んでみました。その内容をザックリ解説してみようと思います。
論文はこちらです。 TinyLFU: A Highly Efficient Cache Admission Policy
いきなりTinyLFUの紹介を始めると混乱するので、ベースとなる技術やアルゴリズムから紹介して、それらをどう組み合わせてTinyLFUが出来上がるかを紹介していきます。そこから論文で紹介されているTinyLFUの拡張のW-TinyLFUの紹介までいきます。
基本的な置換ポリシーの復習
キャッシュが一杯になったとき、置換ポリシー に基づき、新たなアイテムを格納するためにどのアイテムを追い出すかを選択します。あるキャッシュ内のアイテムが他のアイテムよりもアクセスされる確率が高い場合、キャッシュヒット率をあげるために、アクセスされる確率が高い方をキャッシュ内に残しておきたい訳です。
その為に、キャッシュにはアイテムとは別に、どのアイテムを選別するかを決定するためのメタデータを保持し、計算によってそれを求める必要があります。TinyLFUの前に基本的な置換ポリシーをみていきましょう。
LFU
LFU(Least Frequency Used)は文字通り、最も頻繁に使用されるアイテムをキャッシュに残していく戦略です。 データアクセスパターンの確率分布が時間の経過とともに一定である場合は、最も頻繁に使用されるものが最も高いキャッシュヒット率をもたらします。
一方でLFUには2つ問題があります。
- 内部に大規模で複雑なメタデータを維持する必要がある
- 実戦のほとんどではアクセス頻度は時間の経過とともに変化する
1点目については全てのアイテムに対するアクセス回数、時間を保持する必要があります。さらに厳密にやるなら今キャッシュに保持していないアイテムのメタデータも保持する必要があります(Perfect LFU)。2つ目に関しては例えば、今日アクセス頻度の高かった動画が、明日人気であるとは限らないのでキャッシュに入れておく意味が薄れてしまいます。
LRU
LFUの代わりとして検討できるのが時間的局所性を利用するLRU(Least Recently Used)です。最近使ったアイテムは今後も使う可能性が高いだろうと判断し、最も古いアイテムをキャッシュから削除する戦略です。LFUよりもかなりシンプルな実装になり、LFUが対応困難だった時間経過にも対応出来ます。しかし、LRUはLFUよりも多くのキャッシュサイズを必要とします。
TinyLFU
TinyLFU のアーキテクチャは下記。ここでは、Eviction Policy が Cache Victimを選択し、TinyLFU が Cache Victim を新しいアイテムに置き換えることでヒット率の向上が期待できるかどうかを判定します。 下記のアーキテクチャのようにMain Cacheの前段階としてどのアイテムを挿入するかを決定します。
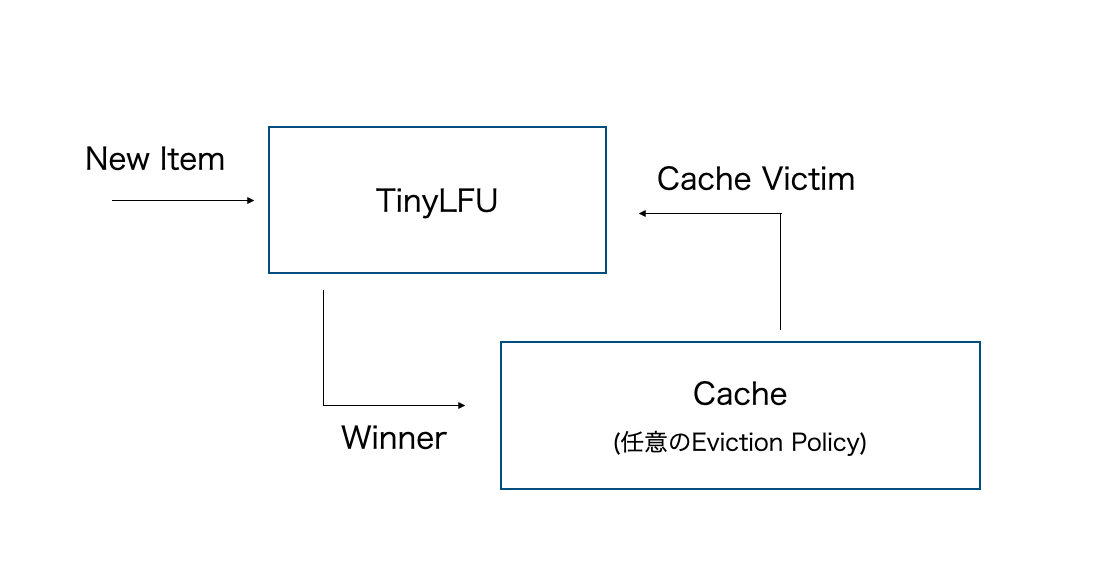
こうすることで、TinyLFUにサイズの大きい統計情報の管理を託すことができます。一方で実戦ではTinyLFUに格納する統計情報が大きくなってしまうので、TinyLFUではこれらを近似して利用します。
TinyLFUのアーキテクチャで利用されているテクニックを詳しくみていきましょう。
Approximate Counting
TinyLFU の重要な要素である Approximate Counting を考えていきます。これはどのようにアクセス頻度を近似するかを提案します。色んな方法がありますが、その中で TinyLFU の基礎となる Bloom Filter と Counting Bloom FIlter を紹介していきます。
Bloom Filter
空間効率の良い確率的データ構造であり、要素が集合のメンバーであるかどうかのテストに使われます。偽陽性(false positive) による誤検出の可能性があるが、偽陰性(false negative) がないのが特徴です。
Bloom Filter は簡単に説明すると k個のハッシュ関数に対応する配列(論文の文脈ではこれをapproximation sketches: 近似スケッチと呼んでいる)のインデックスにビットを立てていく。要素が集合に存在するかを確認したいときはその要素もハッシュ関数にかけて対象ビットが全て立っているかを確認する。下記の例ではk = 3で集合{"a", "b", "c"}に対し、要素 w があるかを判定している例。wは1箇所ビットが立っていないので、集合にwは無いと断定できる。
k 個のハッシュ関数を利用しており、それぞれがキー値を配列位置のいずれかにマッピングする。
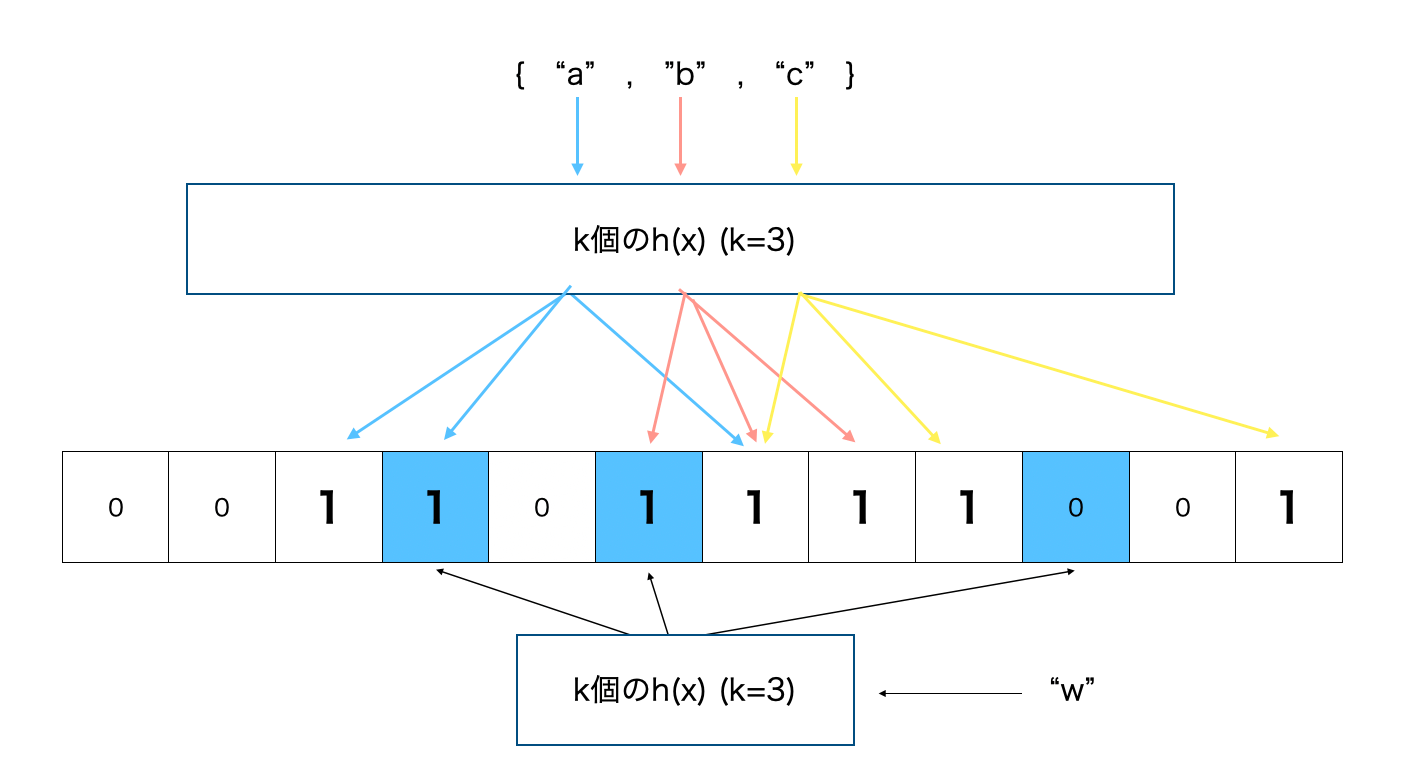
これの強力なところは、データ自体を格納する必要がない為、データ効率が格段に高く、要素数に関わらずO(k)時間で集合内に要素が無いことを確定できる。すごい。
過去にGoでBloom FilterをGoで実装したことがあるのでもし良ければ参考に! Go bloomfilter package
Counting Bloom Filter
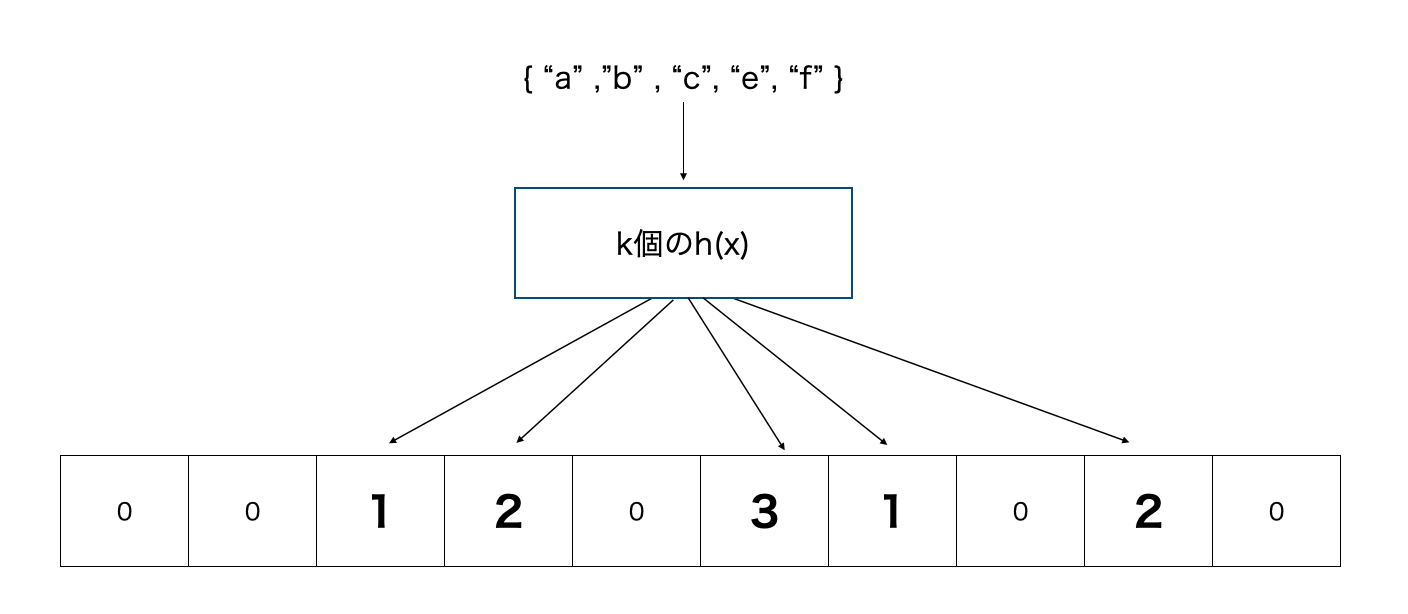
Bloom Filter では要素を削除することが出来ない。その為、Filterの要素をビットではなく nビットのカウンタに拡張している。要素の追加は各配列要素のインクリメントになり、削除する場合、対応する配列要素のカウンタをデクリメントすればいい。これの問題は要素数が大きすぎるとカウンタがオーバーフローする可能性があります。
Freshness Mechanism
TinyLFUの論文ではグローバル・カウンタSを採用し、それをアイテムの挿入の度にインクリメントしていき、Sの値がサンプルサイズ(W)に達すると、Sと近似スケッチのすべてのカウンタを2で割りるリセット法を提案しています。リセット直後は、Sもrefleshされ、S = W /2になります。
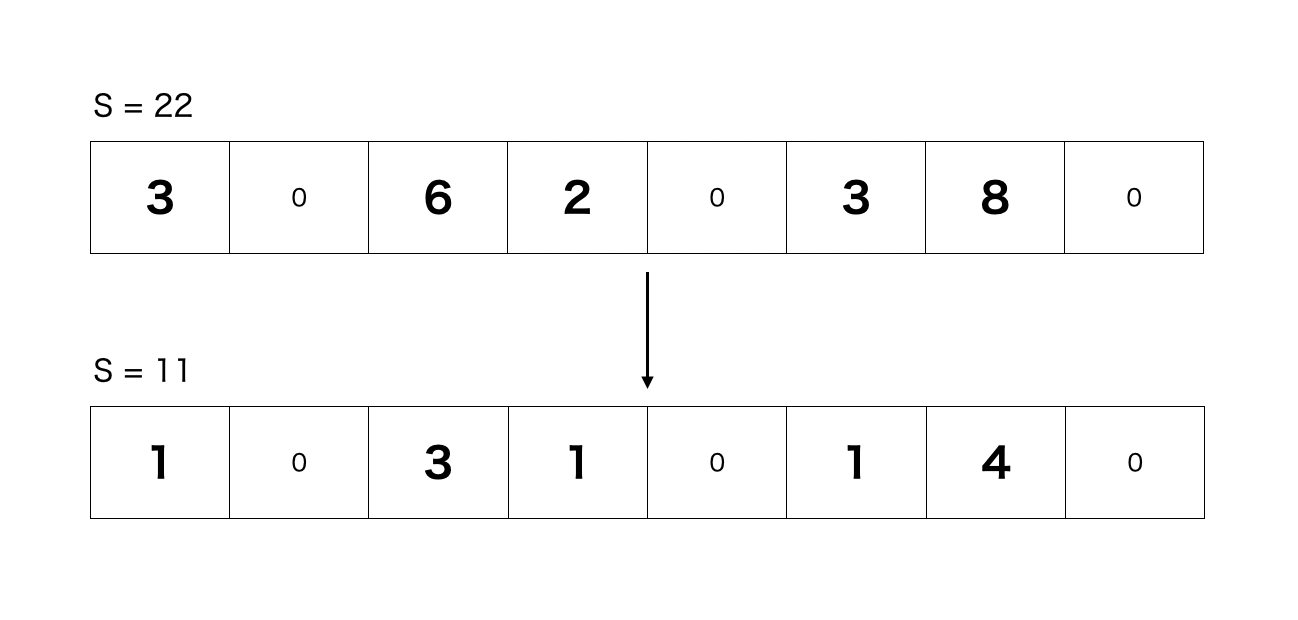
TinyLFUの論文ではリセット法を用いることで、スペースを増やすことなく近似スケッチの精度を向上させることを提案してます。
この操作の欠点は、近似スケッチ内のすべてのカウンタを調べて2で除算する追加の操作が必要になることですが、シフトレジスタを使用することで、2による除算をハードウェア上で効率的に実装することができます。同様に、シフトおよびマスク演算により、複数のカウンタに対して一度にこの演算を実行することができます。
原文では割り算による切り捨て誤差の議論がありますのでもし興味あれば読んでみて下さい。
Space Reduction
TinyLFUの論文で検討されている Small Counters と Doorkeeper をみていきます。
Small Counters
サインプルサイズがWで与えられる場合、カウンタはWまでカウントできるようにする必要があるのでWが大きいとその分カウンタのスペースが要求されます。その為、
- キャッシュ内の全てのアイテムの正確なランキングを決定する必要が無い
- アクセス頻度が
1 / C以上である全てのアイテムはキャッシュに属する - リセット法によおるrefleshを行う
という状況の元で、この論文では与えられたサンプルサイズ W に対して,カウンタを W / C で縮小して実装することを提案しています。
例えば 16K 個のアイテムに対して 2K サイズのキャッシュを考え,この最適化を行わない場合,必要なカウンタサイズは 14 ビットとなる(2^14=16384 > 16K)。この最適化を行うとこの方法を使うと W / C = 8 でカウンタには 3 ビット に減らせます。
Doorkeeper
TinyLFU では Approximate Counting スキームのカウンタのサイズをさらに小さくするために、頻度の低いアイテムに複数ビットのカウンタを割り当てないようにする Doorkeeper 機構を提案しています。
Doorkeeperは、Approximate Counting スキームの前に配置された普通の Bloom Filter として使って実装されます。アイテムが到着すると、まずそのアイテムが Doorkeeper に含まれているかどうかを Bloom Filter でチェックし。Doorkeeper に含まれていない場合は Doorkeeper に挿入され、そうでない場合は後続の main cache に挿入される。アイテムを問い合わせる際には、Doorkeeper とmain cacheの両方を使用します。下記は基本的なTinyLFUのアーキテクチャになります。
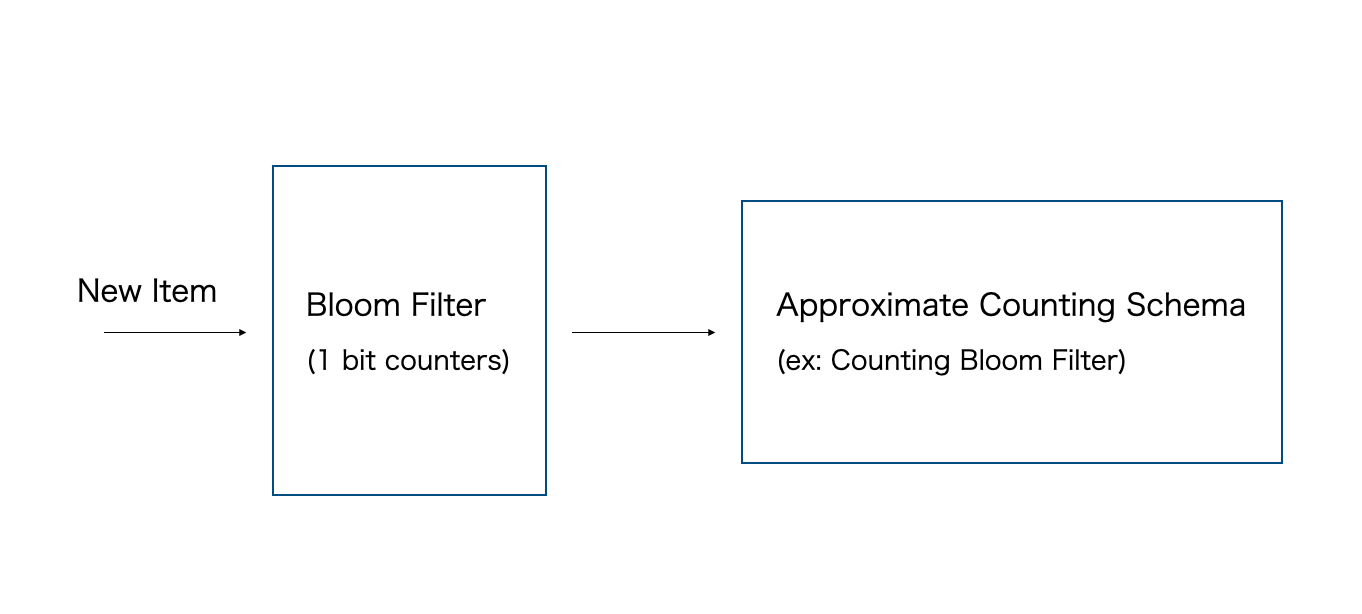
メモリ的には、Doorkeeper は追加のスペースを必要としますが、Approximate Counting スキームに挿入されるユニークなアイテムの量を制限するため、利用するメモリを小さくすることができます。特に、ほとんどの低頻度アイテムには、Doorkeeper では1ビットのカウンタしか割り当てられていません。
W-TinyLFU
実は、理論的な観点からはTinyLFU は LRU よりもHit率が悪いという報告があります。それを改善する為に、W-TinyLFUという機構が提案されています。W-TinyLFUはアドミッションポリシーを採用したメインキャッシュとアドミッションフィルタを持たないウィンドウキャッシュの 2 つのキャッシュ領域から構成されます。
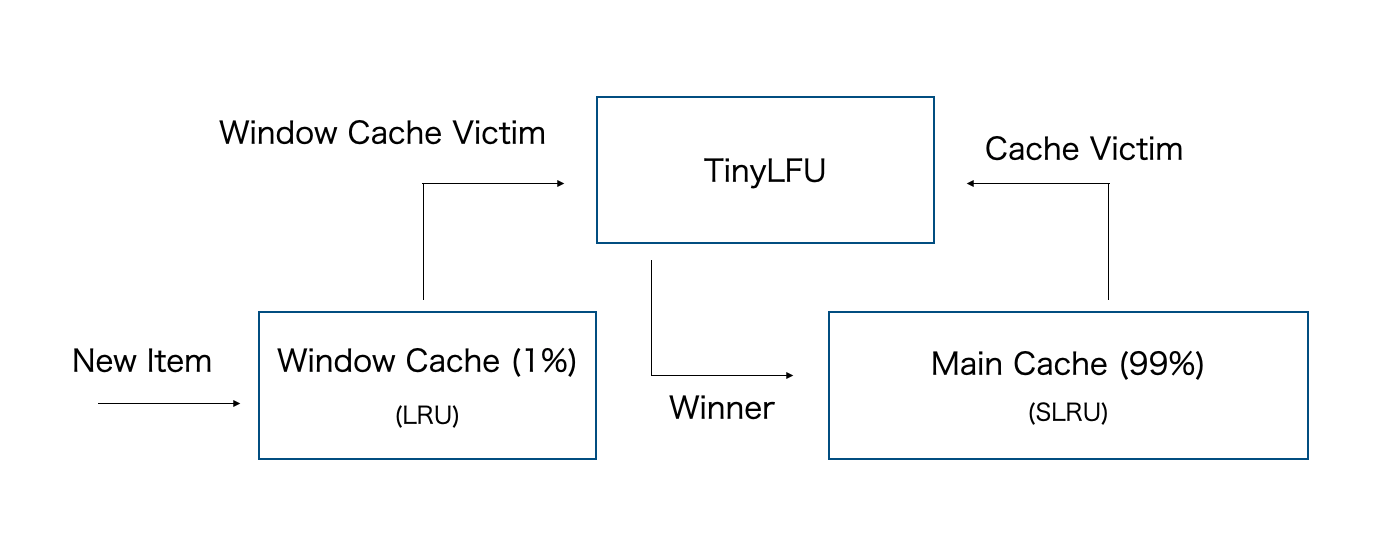
キャッシュミスが発生するたびに、アクセスされたアイテムはウィンドウキャッシュに挿入される。ウィンドウキャッシュのVictimは、その頻度推定値がメインキャッシュのVictimよりも高いか低いかに応じて、メインキャッシュに挿入すべきかどうかを決定するために TinyLFU に渡さます。
このアーキテクチャは汎用的であり、ウィンドウキャッシュとメインキャッシュには任意の退避ポリシーを選択でき、相対サイズも任意です(上の図では1:99)。しかし、このアーキテクチャにおけるウィンドウキャッシュの目的は、最近アクセスされたアイテムを保持することなので、この論文では ウィンドウキャッシュの退避ポリシーを最初に紹介した LRU に設定しています。ウィンドウキャッシュで Victim が発生するとDoorKeeperに送られてフィルタリングされ、フィルタリング後は大きな Segmented LRU キャッシュに要素が格納されます。
Segmented LRU(SLRU) は、LRUを改良したもので、2回以上ヒットしたレコードと1回ヒットしたレコードを別々に格納することで、短期的にキャッシュされた要素の頻度が高いものを区別できるようにしたものです。SLRU は下の図のように、Probation と Protected と呼ばれる2つのLRUで構成されます。
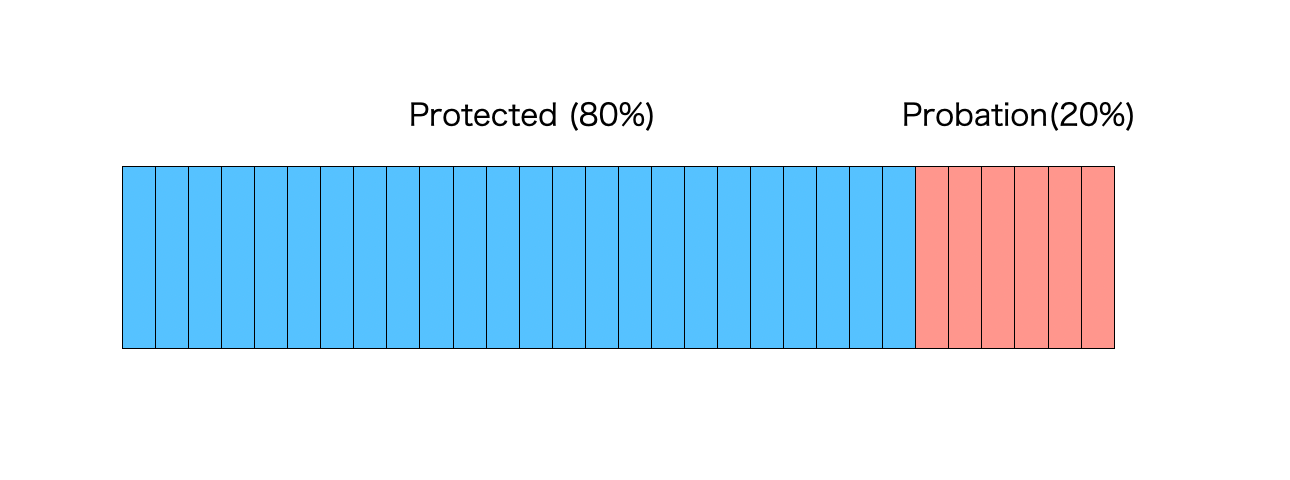
Probation には常に新しいレコードが挿入され、Probation のレコードが再度アクセスされると、Protection に移動されます。Protectionが一杯になると、Probationに戻されます。W-TinyLFU では、SLRU スペースの 80% がセクション Protection に割り当てられています。
Database Internals では TinyLFU としてこちらの W-TinyLFU が紹介されています。
まとめ
TinyLFUを紹介し、その拡張であるW-TinyLFUの概要を紹介しました。僕がよく書くGoではristrettoというキャッシュパッケージが内部でこの考え方を採用しているようです。
もっと詳しく知りたい方は論文を読んでみてください。実戦で使える手札としてこういうコンピュータサイエンスの論文は趣味でどんどん追っていきたいと思います。