Overview
こんにちは pon です。これは「情報検索:検索エンジンの実装と評価」(Buttcher本) Advent Calendar 2020 の記事です。
仕事では主に検索基盤を担当しているので、検索エンジンの内部を知りたくなるのは仕方のないことです。そこでいわゆるButtcher本を読み始めました。

そこで学んだインメモリインデックスは検索に使われる転置インデックスを理解するのにはシンプルである為、情報検索データ構造に関してあまり詳しくない僕のような人間が情報検索を理解する足がかりになるでしょう。
今回はButtcher本で解説されているインメモリインデックスをGoで実装しながら理解していきます。コードはこちらのリポジトリに置いてあります。
転置インデックスとは
転置インデックスに関しては同じアドカレである「情報検索:検索エンジンの実装と評価」(Buttcher本) Advent Calendar 2020 の2日目の記事にて解説されています。この記事では今回実装する スキーマ非依存型インデックス についての解説もあるので、転置インデックスの節だけでも目を通して置くと良いでしょう。
「情報検索:検索エンジンの実装と評価」2章 基本技術 - 人間だったら考えて
転置インデックス実装方針
今回はButtcher本で解説されている手法からなるべくシンプルなデータ構造で転置インデックスを実装していきます。言語は自分が一番慣れているGoで実装していきます。転置インデックスには様々な種類があり、今回は スキーマ非依存型のインメモリな静的転置インデックス を実装していきます。
静的転置インデックス
静的とは途中で内容が変わらないことを意味します。シンプル故に、初めて転置インデックスを勉強する人にとっては良い題材です。
インメモリインデックス
今回はテキストコレクションが全てメモリに収まるとします。検索対象のテキストコレクションがメモリに収まる範囲の場合、インメモリインデックスを実装することができるので、今回はインメモリインデックスを実装していきます。
逆にテキストコレクションがメモリに収まらない場合は分類インデックス、統合型インデックスなどの選択肢があります。詳しくはButtcher本の4.5.2以降で解説されています。
スキーマ非依存型インデックス
また、今回はもっともシンプルな スキーマ非依存型インデックス を実装していきます。これは第2章で出てくるようにドキュメント志向の最適化をせずに、テキストコレクションでの出現位置だけを保持します。
再掲ですが下記の記事でスキーマ非依存型インデックスが解説されています。 「情報検索:検索エンジンの実装と評価」2章 基本技術 - 人間だったら考えて
インデックスを構成するコンポーネント
インデックスを構築するための基本的なコンポーネントは辞書とポスティングリストの二つです。今回はGoで実装していくにあたり辞書とポスティングリストのデータ構造を検討します。
各データ構造は順に解説していきます。全体像はこちらになります。
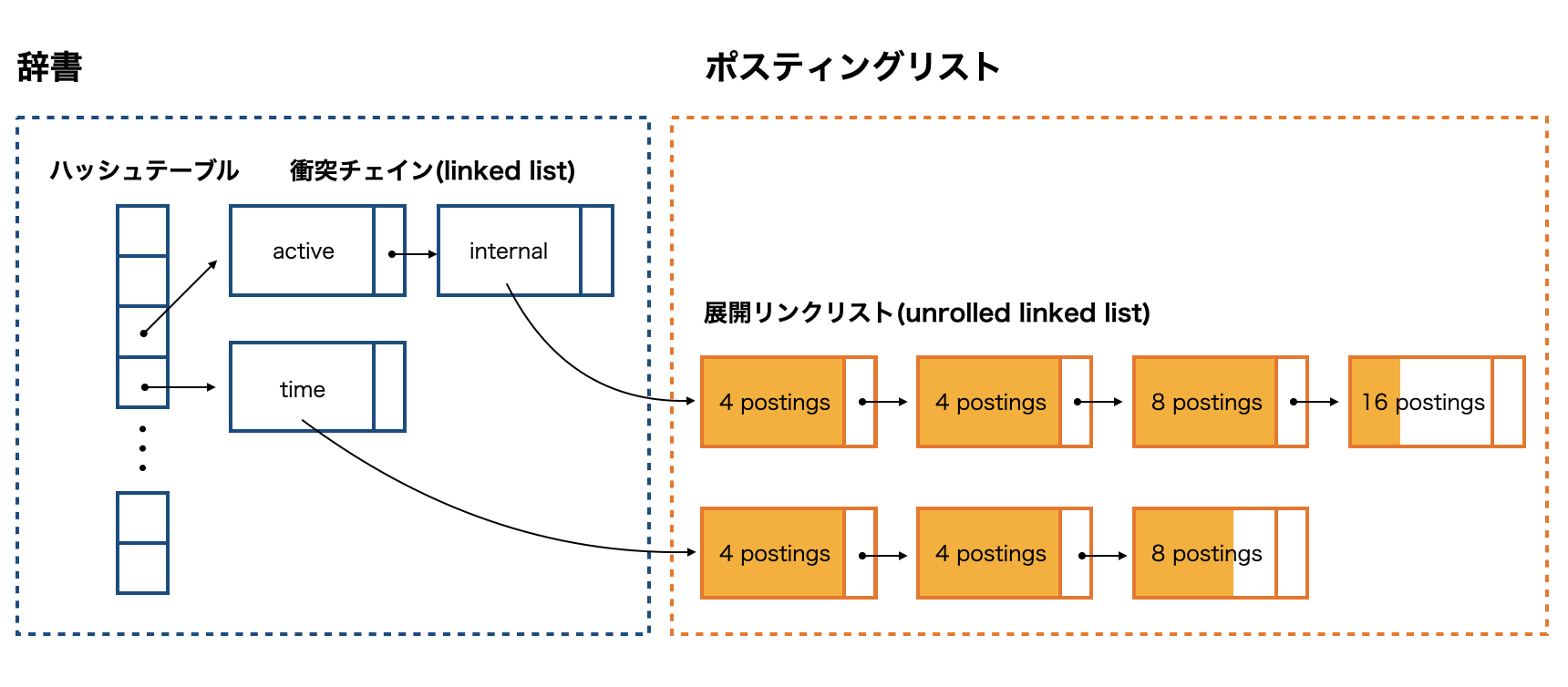
辞書
辞書は検索時にタームの検索に利用されるデータ構造です。本では ソート配列辞書 と ハッシュ配列辞書 の説明がありますが、ハッシュ配列辞書の方がソート配列辞書よりも探索が高速なので(ハッシュ配列辞書はバイナリサーチなどの調査が不要な為)今回はハッシュ配列辞書を使って実装します。
ハッシュ配列辞書はハッシュテーブルを用いて辞書を構築するデータ構造です。ハッシュが衝突した場合は衝突チェインで繋いでいきます。下図はハッシュ配列辞書を表したものです。
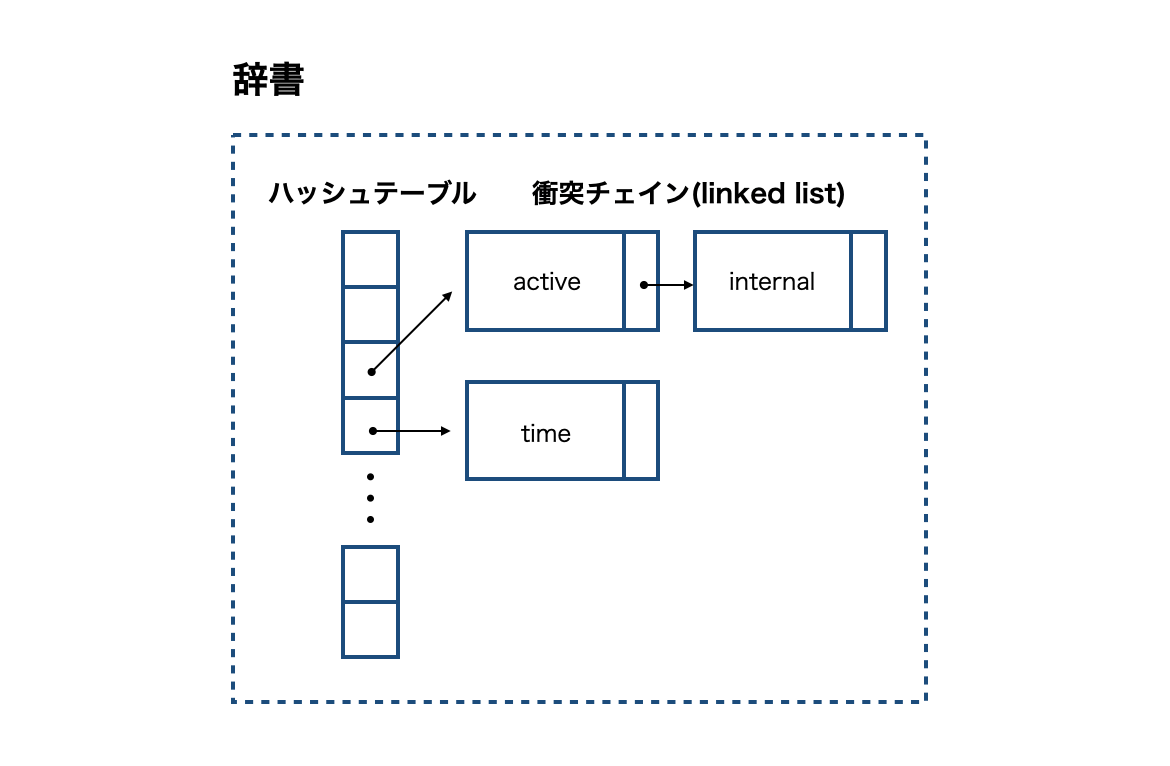
辞書へのアクセスをより高速にするためには単語の出現頻度に現れるジップの法則を考慮する必要があります。テキスト中のほとんどのトークンはごく少数の高頻度トークンで占められているため、この高頻度トークンへのアクセスをなるべく高速にするために辞書でアクセスしやすい位置においておく必要があります。そのためにハッシュテーブルに適用できる2つの手法があります。
後方挿入 (insert-at-nback heuristic)
出現頻度の高いタームはテキストコレクションの早い段階で出現するので、遅れて出てくる衝突したタームはチェインの最後に付加します。こうすることで低頻度のタームはチェインの後ろに置かれることになります。
前方移動 (move to front heuristic)
高頻度で出現するタームはチェインの前方にあることが望まれます。タームがアクセスされるごとにチェインの先頭に移動することによってチェインの先頭に高頻度タームがくるようになります。
ポスティングリスト
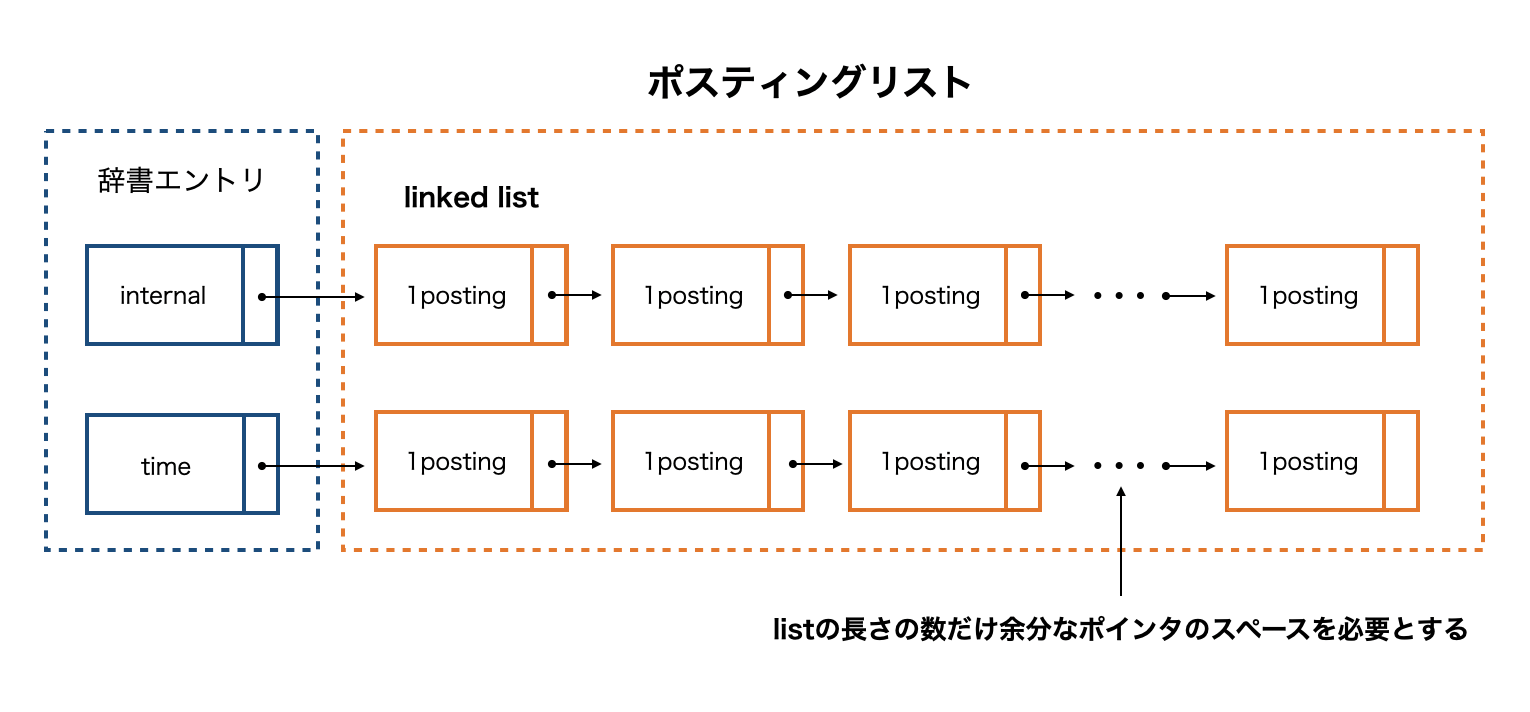
ポスティングリストはコレクション中の位置情報を保持し、この情報は辞書を介してアクセスします。インデックスの構築中は当然ポスティングリストのデータ構造は拡張可能になっていなければいけません。
拡張可能性を考慮して、例えばポスティングリストを linked list として実装すると簡単にポスティングリストは拡張可能ですが、ポスティング1つごとにポインタ分のスペースが必要になってしまうデメリットがあります。下図はlinked listを使った時のポスティングリストを表しています。
そこでこのデメリットを解消しつつ、CPUキャッシュヒット率もあげられるという 展開リンクリスト(unrolled linked list) というデータ構造で実装します。下図は展開リンクリストを使ったポスティングリストを表したものです。これはコンパイラのループ展開の最適化手法が元になっているみたい。
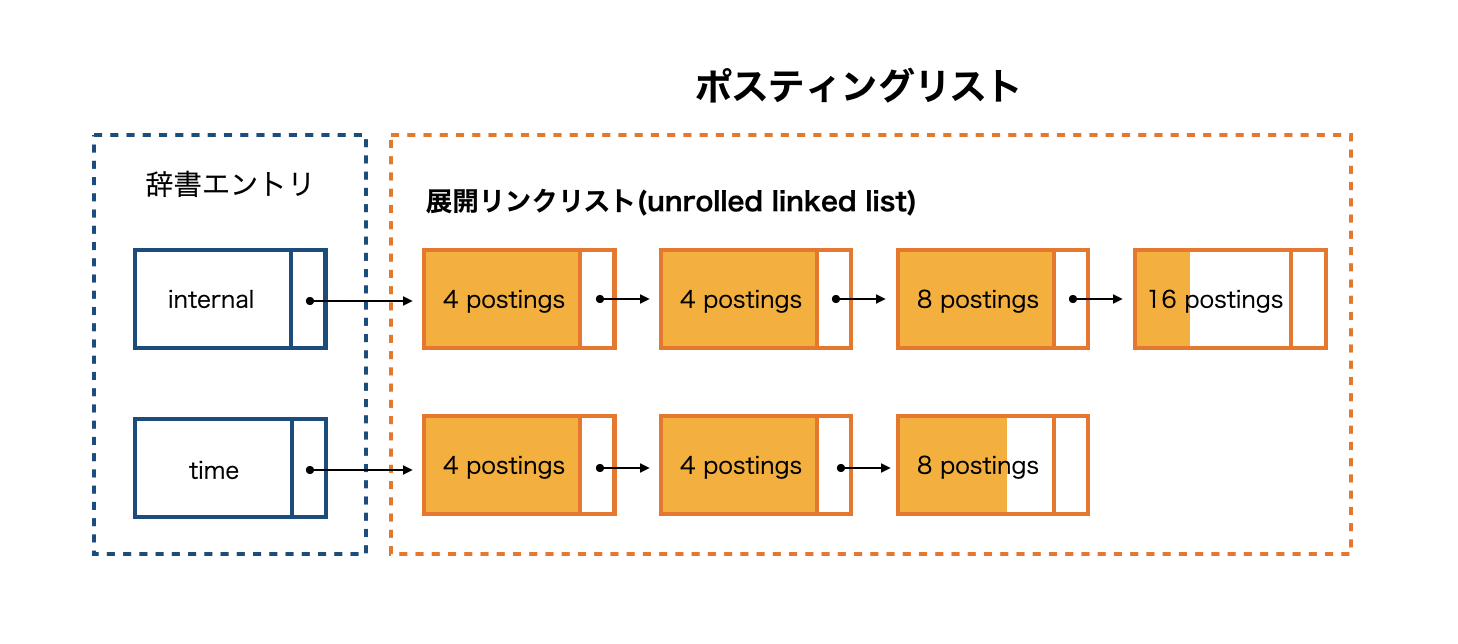
ポスティングリストをグループにまとめることで内部断片量も制御できます。ポスティングリストを拡張する際には新しいgroupにメモリを割り当てるだけなのでreallocを使ったメモリの割り当て変更よりも低コストで拡張できます。1groupの容量は
s = min(limit, max(16, (k - 1) * sTotal))
に従います。limitは1groupに割り当てられる容量の上限値、sTotalはそれまでに割り当てられた容量です。kはプリアロケーションファクタと呼ばれる定数で、ここ内部断片化によるオーバーヘッドとnextポインタ割り当てのオーバーヘッドのトレードオフを調整します。
Goによるインメモリインデックス実装
それでは前節で検討したインデックスを実装していきます。Goのバージョンは執筆時点で最新の v1.15.6 を使います。
テキストコレクション
今回はスキーマ非依存型インデックスを実装する為、テキスト全体を一つのテキストとみなして処理していきます。
dataディレクトリにいつくかの英語のテキストファイルを置き、そこからテキストコレクションを作成します。デバッグ用のシンプルなテキストファイルを用意しています。
# hello1.txt
Hello inverted index.
# hello2.txt
Hello search engines.
# hello3.txt
Many search engines incorporate an inverted index.
テキストコレクションはタームとその出現位置のペアの集合をみなせるので、まずは(term, position)のペアのスライスtermsを作成します。なおエラーハンドリングは省略しています。
package main
type term struct {
term string
pos int
}
type terms []term
var re = regexp.MustCompile("[^a-zA-Z 0-9]+")
func clean(document string) string {
return re.ReplaceAllString(strings.ToLower(document), "")
}
func main() {
datadir := "data"
files, _ := ioutil.ReadDir(datadir)
terms := make(terms, 0)
var pos int
for _, file := range files {
if file.IsDir() {
continue
}
b, _ := ioutil.ReadFile(filepath.Join(datadir, file.Name()))
tokens := strings.Split(string(b), " ") // tokenize
for _, t := range tokens {
pos++
t = clean(t) // テキストの簡単なクリーニング
terms = append(terms, term{
term: t,
pos: pos,
})
}
}
fmt.Println(terms)
// ...
}
今回のtokenizeはSpaceでのスプリットで行なっています。日本語をサポートする場合は、形態素解析ライブラリを移植すれば良いでしょう。
ファイルの中身を見ていき、正規表現を使うclean関数で不要な記号などを取り除いてからtermsに格納していきます。これを実行すると下記の結果が得られます。
# go run main.go
[{hello 1} {inverted 2} {index 3} {hello 4} {search 5} {engines 6} {many 7} {search 8} {engines 9} {incorporate 10} {an 11} {inverted 12} {index 13}]
テキストコレクションをtermとpositionのペアの集合に変換できました。ここまできたら次はデータ構造を用いてインデックスを構築していきます。
データ構造の実装
前節で説明したように辞書にはハッシュテーブルを、ポスティングリストには展開リンクリストを利用します。
辞書のハッシュテーブルに関してはGoのmapがハッシュテーブルの実装なのでこいつを使いましょう。mapの内部実装に関してはGoメンテナの方のブログが勉強になります。postings型はポスティングリストの展開リンクリストを表現する型です。
type dict map[string]*postings
ここでこの後に使うmin関数とmax関数を用意しておきます。
func min(i, j int) int {
if i >= j {
return j
}
return i
}
func max(i, j int) int {
if i >= j {
return i
}
return j
}
続いてpostings型を実装していきます。postings.nextが次のgroupへのポインタを格納し、psフィールドにはテキストコレクション内での位置情報を保持します。
const limit = 32
// schema-independent index
type postings struct {
ps []int
next *postings // 次のgroupへのポインタ
}
func (p *postings) put(pos int, workcnt int) {
if p.next != nil {
p.next.put(pos, workcnt+1)
return
}
if cap(p.ps) <= len(p.ps) {
// 新しい group 割り当て
p.next = &postings{
ps: make([]int, 0, min(limit, max(2, workcnt*2))),
}
p.next.put(pos, workcnt+1)
}
p.ps = append(p.ps, pos)
}
workcntは何個目のgroupかを判断するための引数です。これは記憶容量を割り当てる為に必要です。
また、ここではプリアロケーションファクタを2に固定し、記憶容量をスライスの要素数に置き換えることで実装を簡略化しています。僕の環境は64bitであり、配列の1要素8byteなので初期値割り当て含めてgroupが持つポスティングの数は
min(256, max(16, 0)) = 16byte (2posting)
min(256, max(16, 16)) = 16byte (2posting)
min(256, max(16, 16 + 16)) = 32byte (4posting)
min(256, max(16, 16 + 16 + 32)) = 64byte (8posting)
のように増えていきます。その為、展開リンクリストで紹介した記憶容量の計算式がスライスの要素数の式として変換できます。
s = min(limit, max(2, workcnt*2))
少しだけGoに関して解説しておくと、Goのsliceは配列への参照を持つデータ構造であり、参照先の配列は64bitの世界では1要素8byteの配列です。下のコードはunsafeパッケージを使った配列とスライスの記憶容量の確認コードです。
package main
import (
"log"
"unsafe"
)
func main() {
a := [0]int{}
b := [3]int{1, 2, 3}
c := [5]int{1, 2, 30, 4, 5}
// 配列からスライスを作成
d := b[:3]
e := c[:5]
// 配列は要素の数だけ容量が増えるのが確認できる(8byte×要素数)
log.Println(unsafe.Sizeof(a)) // 0
log.Println(unsafe.Sizeof(b)) // 24
log.Println(unsafe.Sizeof(c)) // 40
// スライスはただの参照なので固定サイズ
log.Println(unsafe.Sizeof(d)) // 24
log.Println(unsafe.Sizeof(e)) // 24
}
これで基本的なデータ構造の実装はできました。実際にこれらを使ってインデックスを構築していきます。debug用に*postingsにgetメソッドを追加した後に ````main```関数の続きを書いていきます。
インデックス構築
func (p *postings) get() []int {
list := make([]int, 0)
return p.getTraverse(list)
}
func (p *postings) getTraverse(list []int) []int {
list = append(list, p.ps...)
if p.next != nil {
return p.next.getTraverse(list)
}
return list
}
func main() {
// 続き ...
dict := make(dict, 0)
for _, t := range terms {
var e *postings
e, ok := dict[t.term]
if !ok {
// 辞書にないなら新しくエントリ追加
e = &postings{
ps: make([]int, 0, 8),
}
dict[t.term] = e
}
e.put(t.pos, 1) // 1個目のgroupなので1を渡す。
}
for t, e := range dict {
fmt.Println("")
fmt.Printf("term: %v\n", t)
ps := e.get()
fmt.Printf("pos: %v\n", ps)
}
}
これを実行してみましょう。狙った通りのスキーマ非依存型の静的インデックスが作成できました。
$ go run main.go
term: engines
pos: [6 9]
term: many
pos: [7]
term: incorporate
pos: [10]
term: an
pos: [11]
term: hello
pos: [1 4]
term: inverted
pos: [2 12]
term: index
pos: [3 13]
term: search
pos: [5 8]
まとめ
本記事では転置インデックスの実装を通してそこで利用できるデータ構造の一部をご紹介しました。Buttcher本の4章ではこの他にもたくさんのデータ構造を紹介しているので、興味ある方はぜひ読んでみてください。 情報検索 :検索エンジンの実装と評価